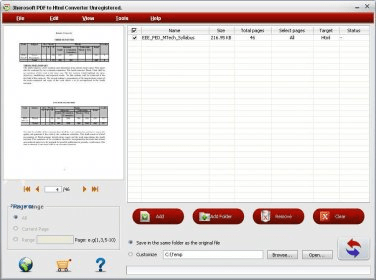
The program extracts text and images from PDF to HTML files. The images are stored in the folder where HTML files are created. It tries to retain the layout of the original files - this doesn't work in most of the PDF files that were tested. This is a standalone program and doesn't require Adobe Acrobat or other tools.
This would be useful for those who wants to extract the text or images from a large number of PDF files. OCR feature is not available - thus, the price is a bit large regarding the features.

You can create, edit, convert, merge, watermark, compress and sign PDF files.








Comments